应用场景
视频监控,法医鉴定, 证据搜集
技术难点
步态识别易受到如下因素干扰:
- 目标相关的: 行走速度, 服饰, 携带物;
- 设备相关的: 相机帧率, 分辨率;
- 环境相关的: 相机视角,光照条件等.
上述干扰因素中,相机视角最棘手。
概览
方法分类: 一种方式按照使用的信息源的不同分成 appearence-based 和 model-based 方法; 另一种是按照数据输入方式不同分成 template-based 和 sequence-based 方法。
按信息源不同
- appearence-based method
这类方法使用平均剪影图(silhouette)提取特征, 代表方法 (GEI, GEnI).- 优点:计算复杂度低
- 缺点:对服饰、携带物、视角等变化敏感
- model-based method
该类方法常利用人体关键点提取步态特征.- 优点:比 Appearence-based 方法更加稳健
- 缺点:(1) 更高计算复杂度 (值得商榷,毕竟分割得到剪影图计算量也不低); (2) 依赖 Pose 估计精度.
按数据处理方式不同
- template-based method
该种方法首先获取每一帧的轮廓图,然后生成步态模板,并通过步态模板提取特征,最后通过欧氏距离或者度量学习的方法学习相应的特征表达。 - sequence-based method
该类方法直接将一组轮廓图序列作为输入。按照提取时序信息的不同可以分为 LSTM-based 和 3D-CNN 方法。这类方法的优点是能够关注每一个轮廓图,获得更多的空时信息。缺点就是计算量比较大。
方法
GaitNet
- Zhang, Ziyuan, et al. “Gait Recognition via Disentangled Representation Learning.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
- Zhang, Ziyuan, et al. “On Learning Disentangled Representations for Gait Recognition.” arXiv preprint arXiv:1909.03051 (2019).
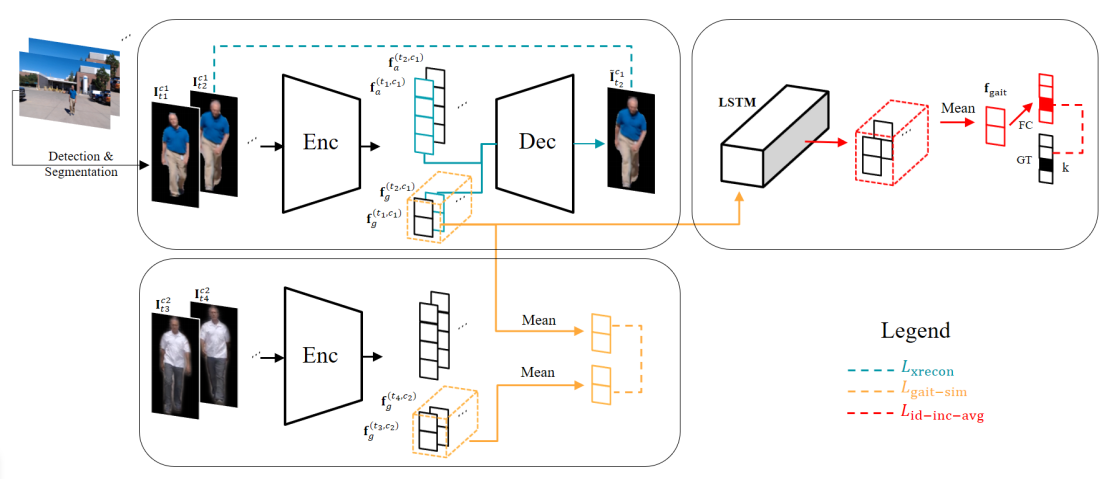
- 对于每个视频帧,编码器求取两种特征:(1) 姿态特征; (2) 外表特征
- 引入两种损函数:
(1) Cross Reconstuction Loss: 融合一帧的 appearence feature 和另一帧的 pose feature;
(2) Gait Similarity Loss: 保证不同人体变化下,同一人的 pose features 是一致的. - LSTM 获得融合后的步态特征
Appearence 特征和 Pose 特征分离
文中提出通过编解码网络的无监督学习方式分离 Appearence 特征和 Pose 特征。
编码网络 $\mathcal{E}$ 视频序列中的一帧图像编码为 appearence 特征 $\bf{f}_a$ 和 pose 特征 $\bf{f}_g$, 这两种特征能够完整地描述输入图像.
另一方面,可通过解码网络 $\mathcal{D}$ 重建输入图像,即
Cross Reconstruction Loss
这里采用 $t_1$ 时刻的 appearence 特征和 $t_2$ 时刻的 pose 特征,是的重构出的图像尽量与 $t_2$ 时刻的图像足够接近:
该损失函数一方面保证两种特征能够重构出视频帧;另一方面在同一视频中, 可将当前帧的 Pose 特征和任一帧的 appearence 特征组对重建同一个目标,达到 appearence 特征在所有视频帧中都相似的目的。
Gait Similarity Loss
为了降低 appearence 特征泄露到 pose 特征的风险,这里使用同一目标的多个视频以提纯 $\bf{f}_g$.
假定在两种拍摄条件 $c_1$, $c_2$ 下拍摄了两段视频,长度分别为 $n_1$, $n_2$. 理想情况下,$c_1$, $c_2$ 的不同不会导致两段视频的步态信息的差异。为此,作者使用了两段视频的平局 pose 特征约束两者相似性:
步态特征聚合
$\bf{f}_g$ 只包含某一时刻的姿态信息, 因此很可能在某个时刻与另外一个人的 pose 特征具有很高的相似性. 因此需要建立时序信息提取一个人的行走模式. 记 $t$ 时刻 LSTM 的输出为 $\bf{h}_t=LSTM(\bf{f}_g^1, \bf{f}_g^2, …, \bf{f}_g^t)$.
由于 LSTM 受最后一帧 $\bf{f}_g^t$ 输入的影响最大, 因此随着时间步长的改变, $\bf{h}_t$ 也会发生改变. 为了降低一个行走周期中任一停止实例的影响,提出了平均化的 LSTM 的输出作为步态特征:
相应的损失函数为:
此外, 视频序列越长, LSTM 算法的预测的可靠性就越高,为此作者对每个时间步长的中间输出结果加权,
整体的损失函数为
GaitSet
Chao, H., He, Y., Zhang, J. and Feng, J., 2019, July. Gaitset: Regarding gait as a set for cross-view gait recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, pp. 8126-8133).
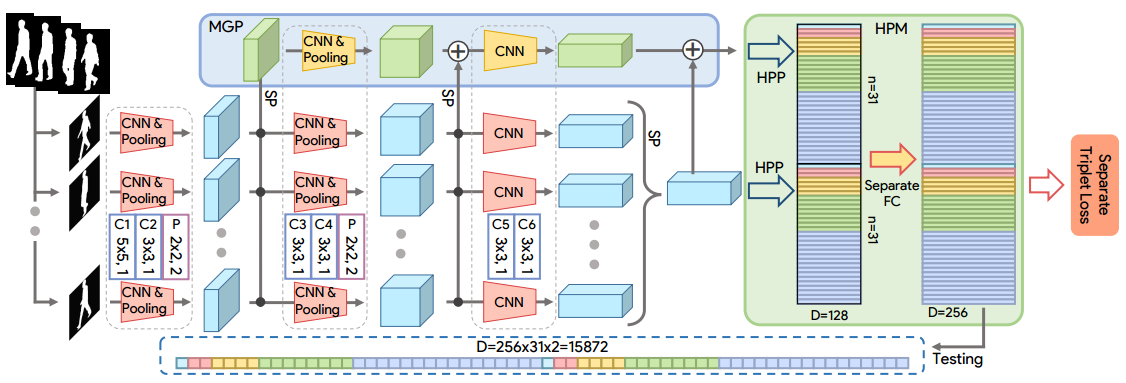
文中的思路是将一组轮廓图当作步态。其依据是,在一个周期内,每个位置的轮廓图具有唯一表征。即使将这些轮廓图乱序,我们仍然能够通过轮廓图的表征将其排列到正确的顺序位置上。因此,可以做出假设:轮廓图已经包含了位置信息,从而步态序列的顺序位置信息并不是必须的。
算法基本步骤:
- 输入一组步态轮廓图,使用 CNN 提取每一帧的 frame-level 特征;
- 使用 Set Pooling 整合多个 frame-level 特征为一个 set-level 特征;
- HPM 将 set-level 特征映射到更具区分度的特征空间。
GaitSet 特点:
- 灵活:输入的轮廓图数量不固定;
- 快速:直接学习步态表示,可通过欧氏距离直接评估两个样本是否相似;
- 高效:环境变化,仍具有很好的泛化性能。
问题公式化表述
对于给定 N 个人的数据集,每个人对应的 ID 为 $y_i, i \in 1, 2, …, N$. 假定某人的步态轮廓图的分布为 $\mathcal{P}_i$. 因此,一个人的所有轮廓图可以表示为 $n$ 个轮廓图的集合 $\mathcal{X}_i={x_i^j}|j=1,2,…,n$. 由此步态识别任务可以公式化为三个步骤:
其中, $F$ 是提取每个轮廓图 frame-level 特征的 CNN; $G$ 为扰动不变性函数,将一组 frame-level 的特征映射为 set-level 特征, 文中通过 Set Pooling 实现; $H$ 为学习 $\mathcal{P}_i$ 的特征表达, 文中通过 Horizontal Pyramid Mapping 实现。
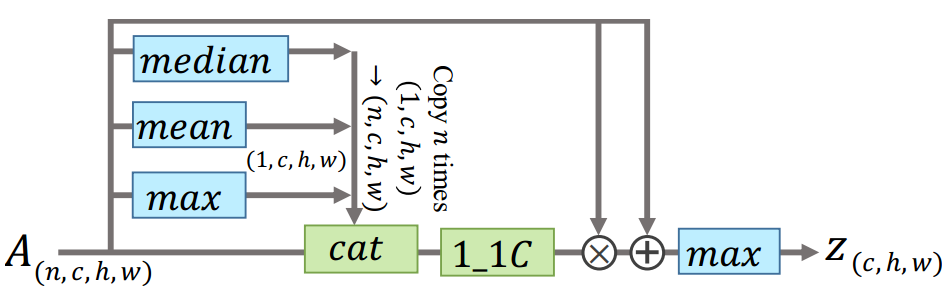
Set Pooling
| 将一组 frame-level 特征 $V=\left\{v^{j} | j=1,2, \dots, n\right\}$ 作为输入, 扰动不变性函数 $G$ 公式化为: | |
| |
其中, $\pi$ 是任一扰动. $G$ 可以抽取集合中任意元素个数作为输入。
Horizontal Pyramid Mapping
思想来源于 Re-id 中将特征图切割为水平条带的方法。
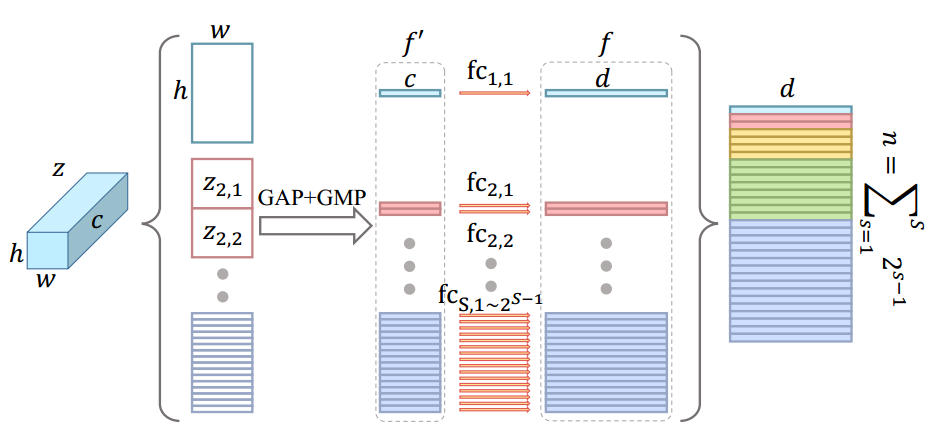
HPM 具有 S 个尺度, 在每个尺度上特征图被切分为 $2^{S-1}$ 个条带. 然后对 3-D 条带全局池化得到 1-D 特征.
Multilayer Global Pipeline
CNN 中不同深度的层具有不同的感受野。作者通过融合 CNN 中深层和浅层特征达到充分利用全局和局部信息的目的。类似与 SSD 中的操作。
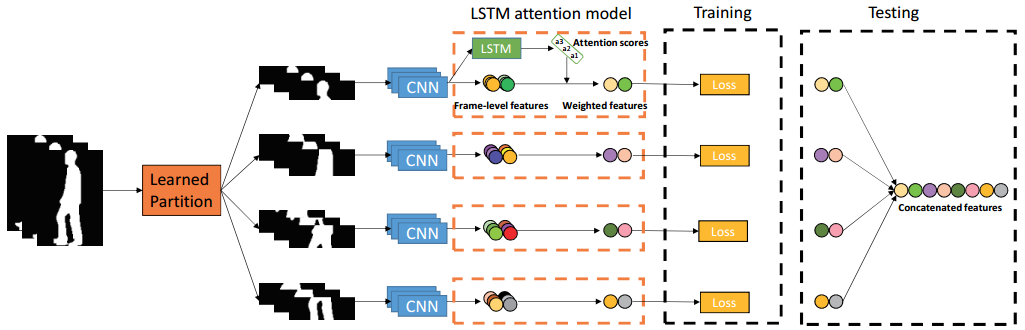
ACL + Local + Temporal
Y. Zhang, Y. Huang, S. Yu, and L. Wang, “Cross-View Gait Recognition by Discriminative Feature Learning,” IEEE Transactions on Image Processing, vol. 29, pp. 1001–1015, 2020.
创新点
- 提出了适合步态识别的 Angle Center Loss;
- 可学习的水平分割和 LSTM 注意力模型.
PoseGait
Liao, R., Yu, S., An, W., Huang, Y., 2020. A model-based gait recognition method with body pose and human prior knowledge. Pattern Recognition 98, 107069.
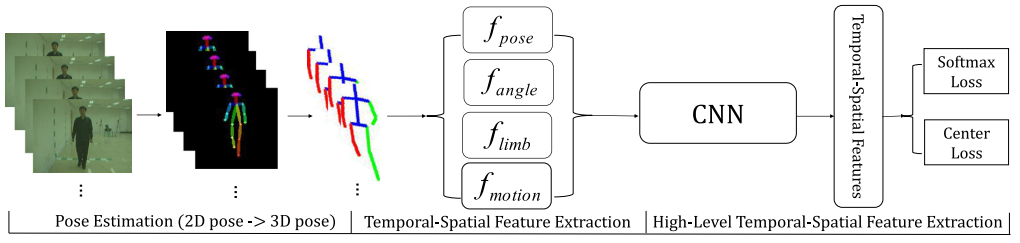
PoseGait 将 3D 人体关键点作为特征。为了提取时序特征,作者根据人体的先验信息设计了手工特征以改善特征提取效率。
三种手工设计特征: 关节角度, 肢体长度,帧间关节运动
==从 CASIA-B 的测试结果看,该方法性能很差,可以尝试把手工特征改为神经网络。==
算法性能评估
- 需要根据场景分别进行评估,如:正常行走,携带箱包,穿大衣等.
- 评估指标: Accuracy@Rank1
CASIA-B
- 前 74 个 subject 作为训练集,后 50 个 subject 作为测试集, Gallery 为 NM #1-4, 剔除了相同视角情形.
| Probe NM #5-6 | $0^{\circ}$ | $18^{\circ}$ | $36^{\circ}$ | $54^{\circ}$ | $72^{\circ}$ | $90^{\circ}$ | $108^{\circ}$ | $126^{\circ}$ | $144^{\circ}$ | $162^{\circ}$ | $180^{\circ}$ | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GaitNet | 93.1 | 92.6 | 90.8 | 92.4 | 87.6 | 95.1 | 94.2 | 95.8 | 92.6 | 90.4 | 90.2 | 92.3 |
| GaitSet | 90.8 | 97.9 | 99.4 | 96.9 | 93.6 | 91.7 | 95.0 | 97.8 | 98.9 | 96.8 | 85.8 | 95.0 |
| PoseGait | 55.3 | 69.6 | 73.9 | 75 | 68 | 68.2 | 71.1 | 72.9 | 76.1 | 70.4 | 55.4 | 68.72 |
| ACL+local+temporal | 92.0 | 98.5 | 100.0 | 98.9 | 95.7 | 91.5 | 94.5 | 97.7 | 98.4 | 96.7 | 91.9 | 96.0 |
| Probe BG #1-2 | $0^{\circ}$ | $18^{\circ}$ | $36^{\circ}$ | $54^{\circ}$ | $72^{\circ}$ | $90^{\circ}$ | $108^{\circ}$ | $126^{\circ}$ | $144^{\circ}$ | $162^{\circ}$ | $180^{\circ}$ | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GaitNet | 88.8 | 88.7 | 88.7 | 94.3 | 85.4 | 92.7 | 91.1 | 92.6 | 84.9 | 84.4 | 86.7 | 88.9 |
| GaitSet | 83.8 | 91.2 | 91.8 | 88.8 | 83.3 | 81.0 | 84.1 | 90.0 | 92.2 | 94.4 | 79.0 | 87.2 |
| PoseGait | 35.3 | 47.2 | 52.4 | 46.9 | 45.5 | 43.9 | 46.1 | 48.1 | 49.4 | 43.6 | 31.1 | 44.5 |
| Probe CL #1-2 | $0^{\circ}$ | $18^{\circ}$ | $36^{\circ}$ | $54^{\circ}$ | $72^{\circ}$ | $90^{\circ}$ | $108^{\circ}$ | $126^{\circ}$ | $144^{\circ}$ | $162^{\circ}$ | $180^{\circ}$ | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GaitNet | 50.1 | 60.7 | 72.4 | 72.1 | 74.6 | 78.4 | 70.3 | 68.2 | 53.5 | 44.1 | 40.8 | 62.3 |
| GaitSet | 61.4 | 75.4 | 80.7 | 77.3 | 72.1 | 70.1 | 71.5 | 73.5 | 73.5 | 68.4 | 50.0 | 70.4 |
| PoseGait | 24.3 | 29.7 | 41.3 | 38.8 | 38.2 | 38.5 | 41.6 | 44.9 | 42.2 | 33.4 | 22.5 | 35.95 |
数据集
| Dataset | #Subjects | #Videos | Environment | Resolution | Format | Variations |
|---|---|---|---|---|---|---|
| CASIA-B | 124 | 13,640 | Indoor | 320×240 | RGB | View, Clothing, Carrying |
| USF | 122 | 1,870 | Outdoor | 720×480 | RGB | View, Ground Surface, Shoes, Carrying, Time |
| OU-ISIR-LP | 4,007 | − | Indoor | 640×480 | Silhouette | View |
| OU-ISIR-LP-Bag | 62,528 | − | Indoor | 1280×980 | Silhouette | Carrying |
| FVG | 226 | 2,856 | Outdoor | 1920×1080 | RGB | View, Walking Speed, Carrying, Clothing, Background, Time |