本博客主要总结自 Attention? Attention?, 感谢作者辛勤的总结.
注意力机制可以理解为一种元素重要性加权机制.
Seq2Seq 模型的有什么问题
seq2seq 模型最早出现在语言模型中 (Sutskever, et al. 2014). 一般而言, 该方法能将输入序列 (source) 转换为新的输出序列 (target), 且输入输出序列长度任意.
seq2seq 是一种 encoder-decoder 结构, 包含:
- encoder: 将输入序列压缩为固定长度的 context vector (或 sentence embedding / thought vector)
- decoder: 将 context vector 作为初始值, 输出变换后的序列. 早期的工作仅仅将编码网络的最终状态作为初始值.
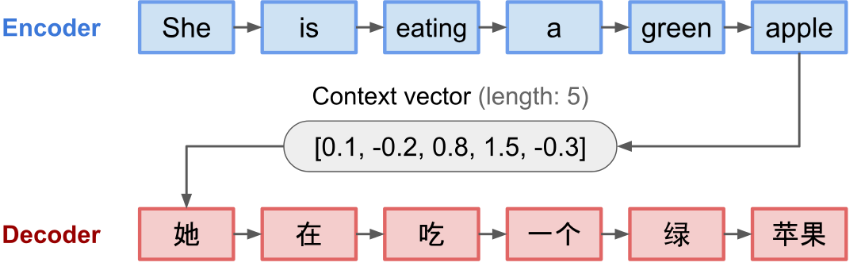
缺点: 固定长度 context vector 无法处理长句子.
注意力机制产生
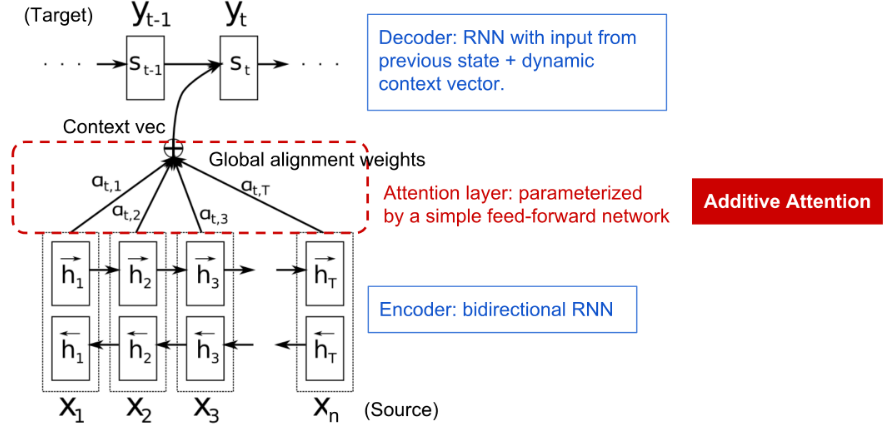
注意力机制产生的背景主要是解决神经机器翻译(NMT, Bahdanau et al., 2015)中长源句子的记忆. 不是通过在编码器最后的隐藏状态构建一个单一的 context vector, 而是在源输入和 context vector 之间建立短接 (shortcuts). 从而 context vector 可以利用整个输入序列的信息, 无需担心遗忘. 由此, context vector 包含了三段信息:
- 编码器的隐藏状态
- 解码器的隐藏状态
- 源序列和目标序列的对齐信息
定义:
- 源序列: $\mathbf{x}=\left[x_{1}, x_{2}, \dots, x_{n}\right]$, 长度为 $n$
- 目标序列: $\mathbf{y}=\left[y_{1}, y_{2}, \dots, y_{m}\right]$, 长度为 $m$
- 编码器: $\boldsymbol{h}_{i}=\left[\overrightarrow{\boldsymbol{h}}_{i}^{\top} ; \overleftarrow{\boldsymbol{h}}_{i}^{\top}\right]^{\top}, i=1, \ldots, n$
- 在位置 $t (t=1,\ldots,m)$ 处的单词, 解码器具有隐藏状态 $\boldsymbol{s}_{t}=f\left(\boldsymbol{s}_{t-1}, y_{t-1}, \mathbf{c}_{t}\right)$, context vector $\mathbf{c}_t$ 是输入序列隐藏状态的和.则 $y_t$ 出的 context vector 满足其中, 单词 $y_t$ 和 $x_i$ 的对齐程度可表示为
对齐模型根据对齐程度, 为一对位置 $i$ 处的输入和 $t$ 处的输出分配一个分数 $\alpha_{t,i}$.
注意力机制家族
Self-Attention
Self-attention, 又称 intra-attention, 能将单个句子中不同的位置关联起来. 主要应用场景包含机器阅读, 抽象总结或图像描述生成.
Soft vs Hard Attention
soft 和 hard 的区别在于是利用整张图像还是图像块.
- soft-attention: 对齐权重通过学习得到, 并软释放到源图像上的所有图像块;
- Pro: 模型平滑可微
- Con: 源图像较大时很耗资源
- hard-attention: 一次只选取图像中的一个图像块.
- Pro: 更低计算量
- Con: 模型不可微, 需要更复杂的技术进行训练, 如 varience reduction 或深度强化学习.
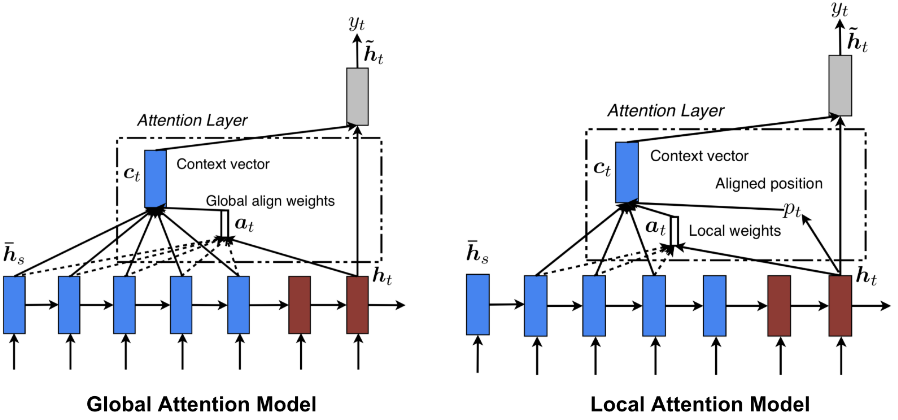
Global vs Local Attention
全局注意力机制和软注意力机制比较像, 而局部注意力机制结合了 hard 和 soft, 使得模型可微.
Transformer
Transformer 完全构建于 self-attention 机制上, 无需使用序列对齐的循环结构. Transformer 的主要组件是 multi-head self-attention 机制.
Key, Value and Query
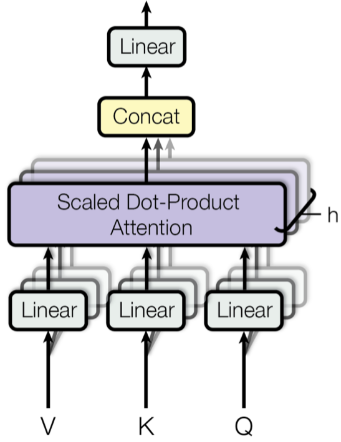
Transformer 将输入的编码表达为一组 key-value 对 $(\mathbf{K, V})$, 两者的维度和输入序列长度一样, 记为 $n$. 在 NMT 中, keys 和 values 都是 encoder hidden states. 在解码器中, 之前的输出被压缩为 query ($\mathbf{Q}, 维度为 m$), 通过映射该query 和 keys, values 组 作为之后的输出.
Transformer 采用了 scaled dot-production attention, 即输出为 values 的加权和, 其中每个 value 的权值由 query 和所有 keys 的点乘决定.
Multi-Head Self-Attention
Encoder
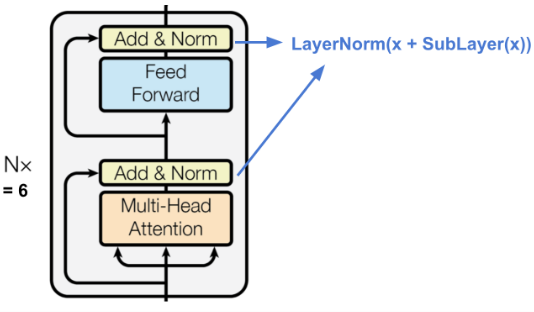
编码器生成从具有无限可能内容中定位特定片段信息的注意力表示.
- 包含 N=6 的完全相同的层堆叠
- 每一层具有一个 multi-head self-attention layer 和一个简单的全连接前向网络
- 每个 sub-layer 采用 residual 连接和 layer normalization. 所有的 sub-layers 输出数据具有相同的维度 $d_{model} = 512$
Decoder
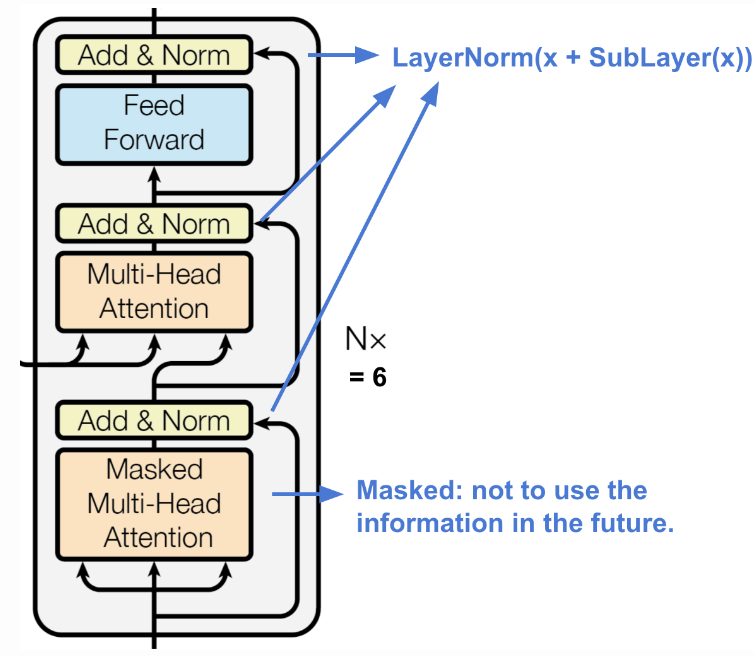
解码器具有从编码表示中恢复信息的能力.
- 包含 N=6 的完全相同的层堆叠
- 每层具有两个 multi-head attention 机制的子层和一个全连接前向网络
- 每个子层采用了 residual connection 和 layer normalization
Full Architecture
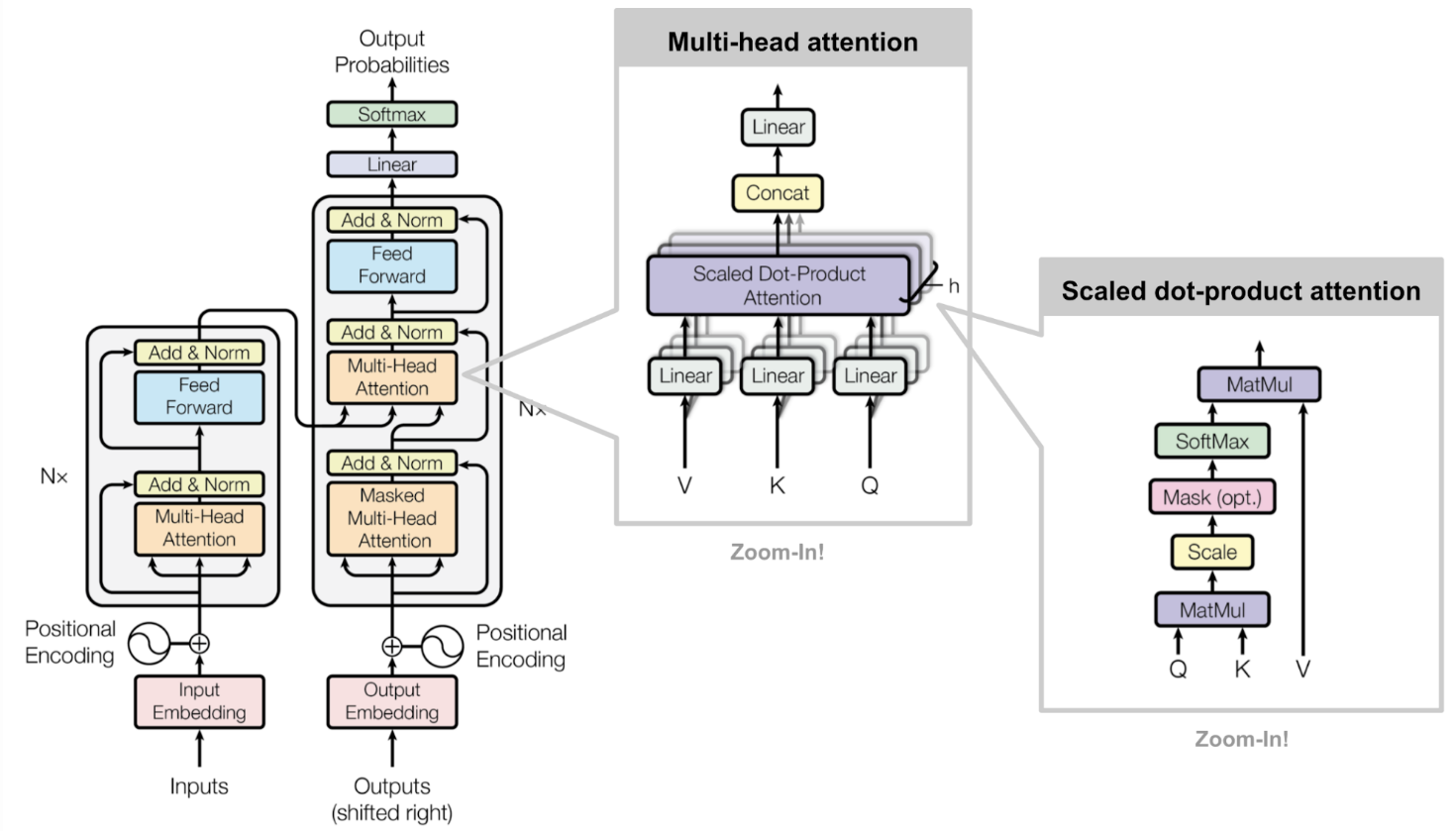
- 源和目标序列首先通过 embedding layers 生成具有相同维度 $d_{model}=512$ 的数据
- 为了保存位置信息, 采用了正弦波位置编码方式, 并叠加至 embedding 的输出