概述
人脸姿态不变处理方法可以分为两类:
- 手工构造或学习姿态不变特征: 此类方法主要存在两个问题, 一是需要在不变性和可区分性之间找到平衡, 因此对于大的姿态变化性能不好; 二是数据通常呈现重尾分布, 某些情形下模型泛化能力有限;
- 合成正脸人脸图像: 主要包含两类方法, (1) 3D 几何变换法, 该类方法难以有效恢复人脸细节; (2) 数据驱动方法, 如 VAE, GAN-based 的方法. 基于 GAN 的方法是我们重点关注和讨论的方法,
正脸合成问题理解:
- 优化角度: 病态问题, 若无先验知识约束, 将会存在多个解;
方法总结
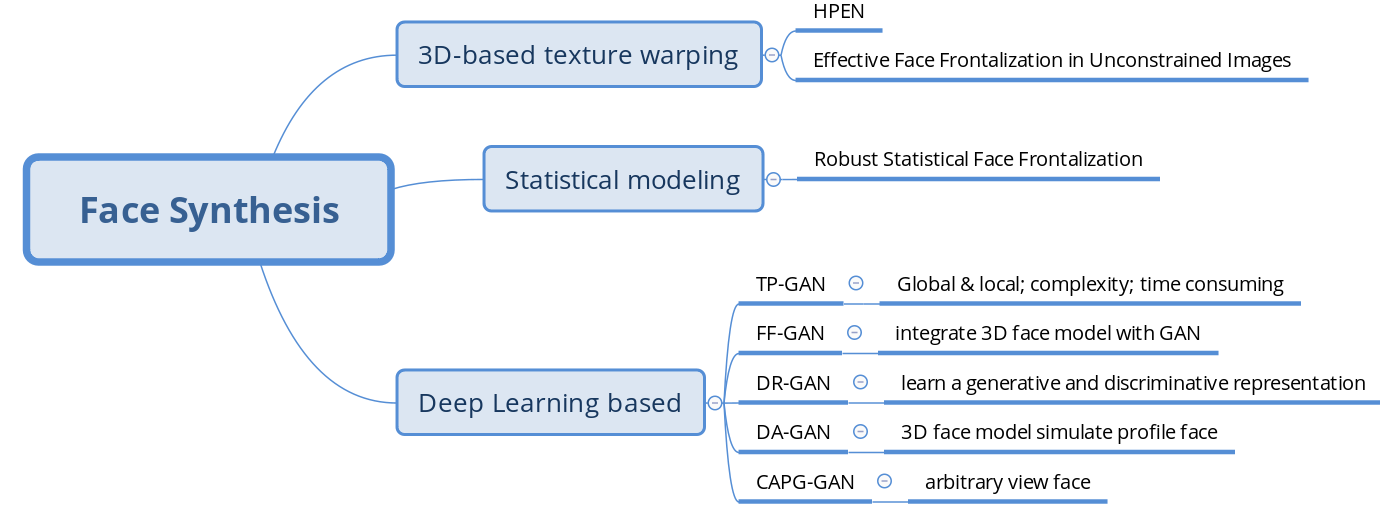
TP-GAN
Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis, 2017, ICCV.
创新点:
- 提出了全局和局部感知的对抗神经网络结构;
- 联合了数据分布 (adversarial training) 先验和人脸领域知识先验 (symmetry & identity perserving loss);
- 首次尝试将合成人脸应用到识别问题中.
符号定义:
- $I^F$: 正脸图像 (frontal image)
- $I^P$: 侧脸图像 (profile image)
- $D_{\theta_D}$: 鉴别器, 区分 $I^F$ 和 $G_{\theta_G} (I^P)$
数据需求: $\{I^F, I^P\}$ 图像对
网络结构特点
Insight: 由于整幅图像的所有空间位置共享滤波器, 因此全局网络无法有效恢复局部细节和旋转人脸.
生成网络
1) 全局生成器 $G_{\theta^g}$
- 包含降采样生成器 $G_{\theta_E^g}$ 和升采样解码器 $G_{\theta_D^g}$;
- 引入 skip layers 的目的在于多尺度融合;
- 中间输出为 256 维的特征向量 $v_{id}$, 用于identity classification. 此外, 连接 100维高斯随机噪声建模不止于姿态和 ID 的变化.
2) 局部生成器 $G_{\theta^l}$
- 每个 $G_{\theta_i^l}$, $i \in \{0, 1, 2, 3\}$ 皆采样 Encoder-Decoder 结构, 但是没有全连接的 bottleneck layer.
3) 信息融合
- 融合四个局部通路为一个特征张量
- template landmark location
- max-out 融合策略减少拼接伪影
- 融合全局和局部特征张量
对抗网络
采用交替训练方式训练 $D_{\theta_D}$ 和 $G_{\theta_G} (I^P)$.
$D_{\theta_D}$ 输出采用 2x2 的概率图替代 1 维标量. 每个概率值对应某个人脸的区域而非整个人脸, 从而聚焦到每个语义区域.
合成损失函数
1) Pixel-wise Loss
- pixel-wise L1 loss
- 应用点: global 网络, local 网络, 最终输出
1) Symmetry Loss
- 利用人脸的对称性解决自遮挡问题
- 应用点: 原始像素空间和 Laplacian 图像空间 (对光照变化不敏感);
- 操作方式: 选择性水平翻转输入数据, 使得遮挡部分处于右侧; 另外, 仅 $I^{pred}$ 参与对称损失计算
1) Adversarial Loss
1) Identity Preserving Loss
PIM
Towards Pose Invariant Face Recognition in the Wild, 2018, CVPR
创新点:
- 正脸化子网络 (FFN) 和鉴别学习子网络 (DLN) 端到端联合优化;
- FFN 采用双路径 GAN, 同时感知全局结构和局部细节;
- DLN 为人脸识别卷积神经网络.
CAPG-GAN
Pose-Guided Photorealistic Face Rotation, 2018, CVPR
CAPG-GAN: Couple-Agent Pose-Guided Generative Adversarial Network
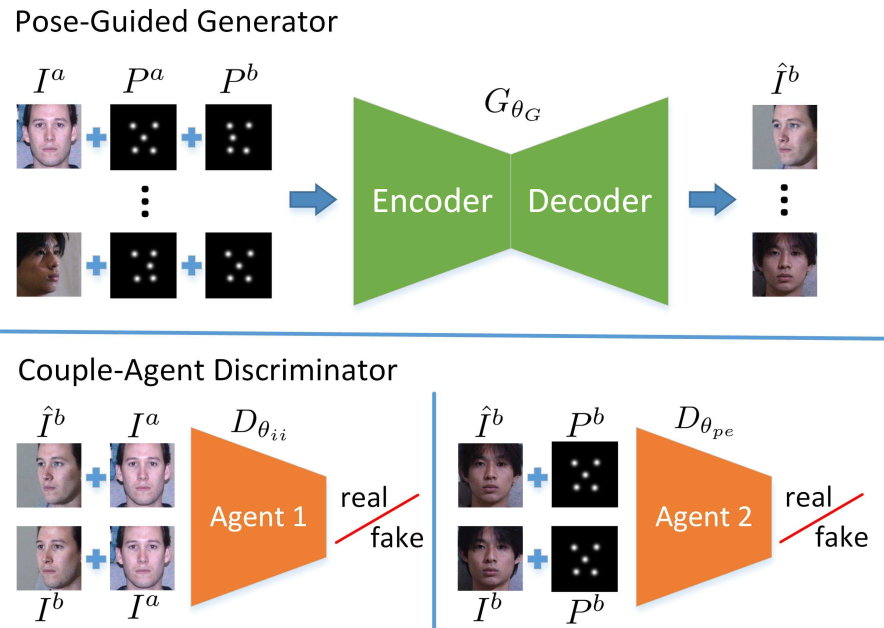
创新点:
- 合成任意视角人脸;
- 使用 landmark heatmaps 作为姿态引导生成器的控制信号合成人脸;
- 偶联鉴别器 (Couple-Agent Discriminator) 有效利用了姿态和局部结构的领域先验知识,强化合成图像真实性;
网络结构
Pose-Guided Generator
- 生成器 $G_{\theta_G}$ 采用 U-Net 结构;
- landmark detector 离线获得 landmark 信息;
- 5 个关键点的 heatmaps 编码为 pose embeddings;
Couple-Agent Discriminator
Agent 1
- 将源图像 $I^a$ 作为条件, 生成器输出 $\hat{I}_b$ (或者目标自然图像 $I^b$) 与 $I^a$ 组成图像对作为输入;
- 同 TP-GAN 类似, 输入图像对映射为概率图, 概率图中的每个位置对应这局部区域
因此, Agent 1 不但能区分合成人脸和真实人脸, 还能学习旋转姿态的差异.
Agent 2
结构同 Agent 1, 不同的是将 pose embeddings $P^b$ 作为条件, 生成器输出 $\hat{I}_b$ (或者目标自然图像 $I^b$) 与 $P^b$ 组成输入对.
损失函数
包含了四个损失, 分别是
- multi-scale pixel-wise loss: 约束图像内容的一致性
- conditional adversarial loss ($L_{adv}$): 整合领域先验
- identity preserving loss: 使用预训练的 light-CNN 作为特征提取器.
- total variation regularization: 旨在减轻图像伪影.
Ablation Study
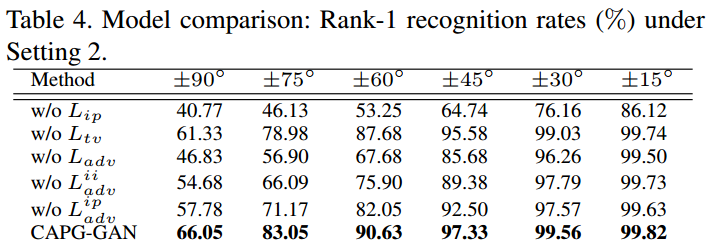
一些结论:
- 无 $L_{adv}$, 生成的图像很模糊;
- identity preserving loss 对模型性能影响最大, total variation regularization 影响最小.
FaceFeat-GAN
FaceFeat-GAN: a Two-Stage Approach for Identity-Preserving Face Synthesis (2018-arXiv)
目的: 合成丰富多样且身份不便的人脸.
方法: 两阶段合成法, 第一阶段生成不同特征, 第二阶段为特征到图像渲染.
Introduction
Previous works:
将 identity label 喂给生成器 G 引导合成过程. \
缺点: facial identity 十分复杂, 仅仅将 identity label 作为监督是不够的, 无法合成高质量图像;利用相同 ID 的图像对, 如 TP-GAN, FF-GAN. \
缺点: 限制了图像的多样性.
Proposed method:
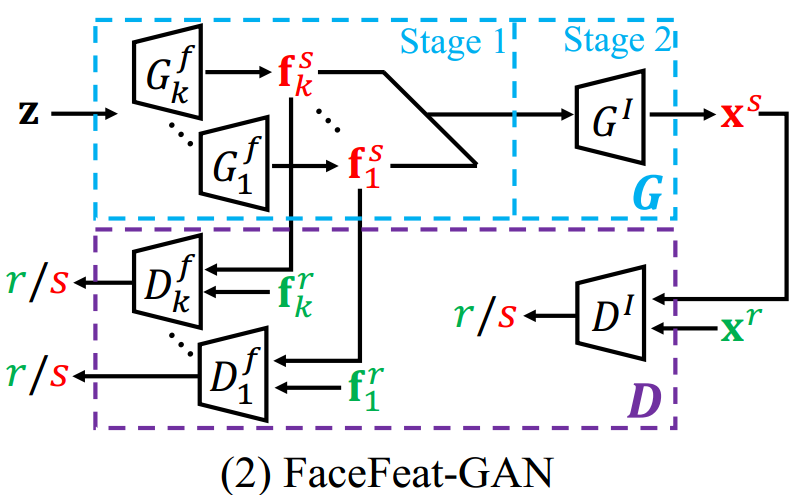
第一阶段: 引入一组特征生成器 $\{G_i^f\}_{i=1}^k$ 生成一组人脸特征 $\{\textbf{f}_i^s\}_{i=1}^k$. 其中 $k$ 表示生成器的个数, 每个生成器对应不同的人脸属性, 如姿态, 表情, 年龄等;
第二阶段: 图像生成器 $G^I$ 将所有生成的特征作为输入, 并输出合成图像.
$G_i^f$ 与 $D_i^f$ 在语义特征域对抗合成人脸特征, $G^I$ 和 $D^I$ 在图像域中对抗, 生成人脸图像.
Related Works
Identity-Preserving Face Synthesis
- FaceID-GAN: 三方博弈, 生成器 G 与鉴别器 D 博弈生成图像, 与 ID 分类器 C 博弈保持 ID 信息.
由于像素级监督导致生成的多样性降低, 应用范围有限. 这些方法通常只能处理多对一的情形, 如正脸化.
VAE
- Attribute2image: 缺点, 生成图像模糊 (缺少鉴别器).
- CVAE-GAN: 联合条件 GAN 和条件 VAE. 由于解码器忽略了输入的随机性, 限制了生成结果的多样性.
- Towards Open-Set Identity Preserving Face Synthesis: 使用不同属性图像作为目标输出图像. 显而易见, 属性图像并不总是具有相同的 ID, 从而导致 ID 信息丢失.
Methods
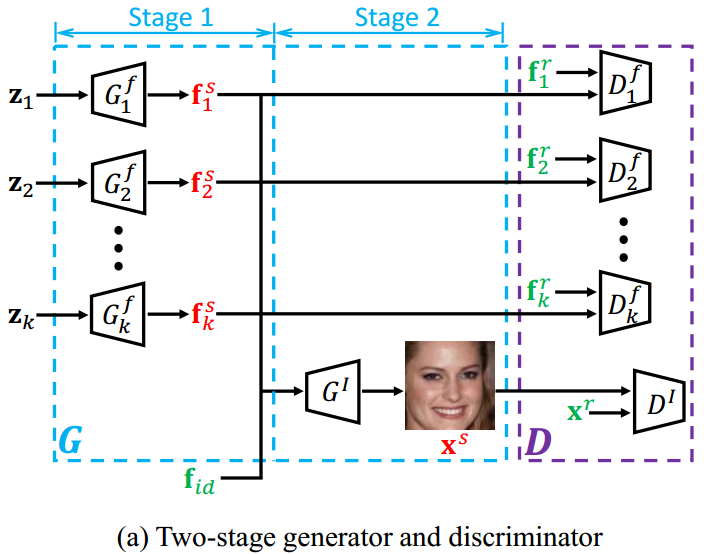
图像合成过程分解为两个阶段:
- 第一阶段: 输入随机变量 $\{\textbf{z}_i\}_{i=1}^k$ 经过生成器组 $\{G_i^f\}_{i=1}^k$ 获得一组特征 $\{\textbf{f}_i^s\}_{i=1}^k$;
- 第二阶段: 使用生成器 $G^I$ 解码特征组 $\{\textbf{f}_i^s\}_{i=1}^k$, 合成图像 $\textbf{x}^s$. 同时, $G^I$ 也利用 ID 特征 $\textbf{f}_{id}$ 获得 ID 信息.
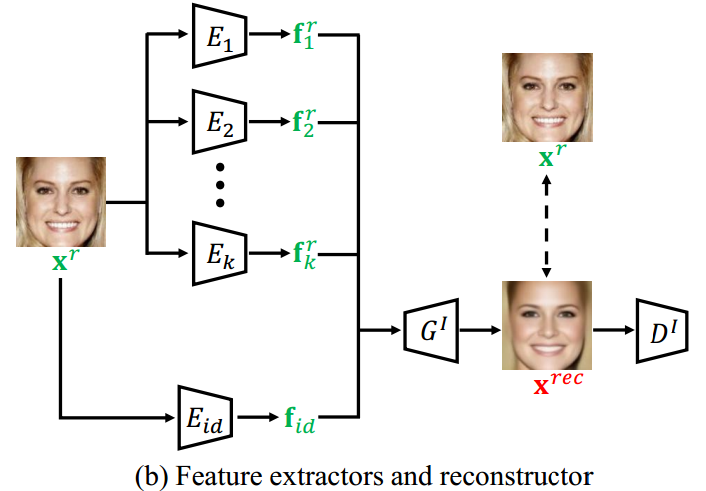
为了保证每个阶段合成结果的真实性, 引入了特征鉴别器 $\{D_i^f\}_{i=1}^k$ 和图像鉴别器 $D^I$.
与传统 GAN 不同的是, FaceFeat-GAN 不但生成 fake 图像, 还重建输入图像从而获得像素级监督信息. 特别地, 引入一组特征提取器 $\{E_i\}_{i=1}^k$ 从输入图像 $\textbf{x}^r$ 中提取特征 $\{\textbf{f}_i^r\}_{i=1}^k$, 人脸识别模块 $E_id$ 用于提取 ID 特征 $\textbf{f}_{id}$. 然后相同的 $G^I$ 将这些特征作为输入生成 $\textbf{x}^{rec}$.
特征提取器
- 3DMM 特征 $\textbf{f}_1^r=E_1(\textbf{x}^r)$ 建模姿态和表情;
- 一般特征 $\textbf{f}_2^r=E_2(\textbf{x}^r)$ 表示其他人脸的变化.
(1) Identity 特征 $E_{id}(\textbf{x}^r)$ \
编码 ID 信息. 用于提取输入图像 $\textbf{x}^r$ 的特征为 $\textbf{f}_{id}$. 模型训练过程采用交叉熵损失.
(2) 3DMM 特征 $E_1(\textbf{x}_1^r)$