人体姿态估计可以分为两类方法, 分别是:
- Top-down: (two-step framework) 先使用人体检测算法检测人体, 然后逐人体估计关键点
缺点: 该方法严重依赖人体检测算法 bounding box 的准确性.
- Bottom-up: (part-based framework) 首先检测人体部件(关键点), 然后集成这些人体关键点组成人体姿态.
缺点: 拥挤人群难以估计准确; 此外, 仅仅利用二级信息(关键点),失去从全局姿态中捕捉身体部件的能力.
RMPE: Regional Multi-Person Pose Estimation
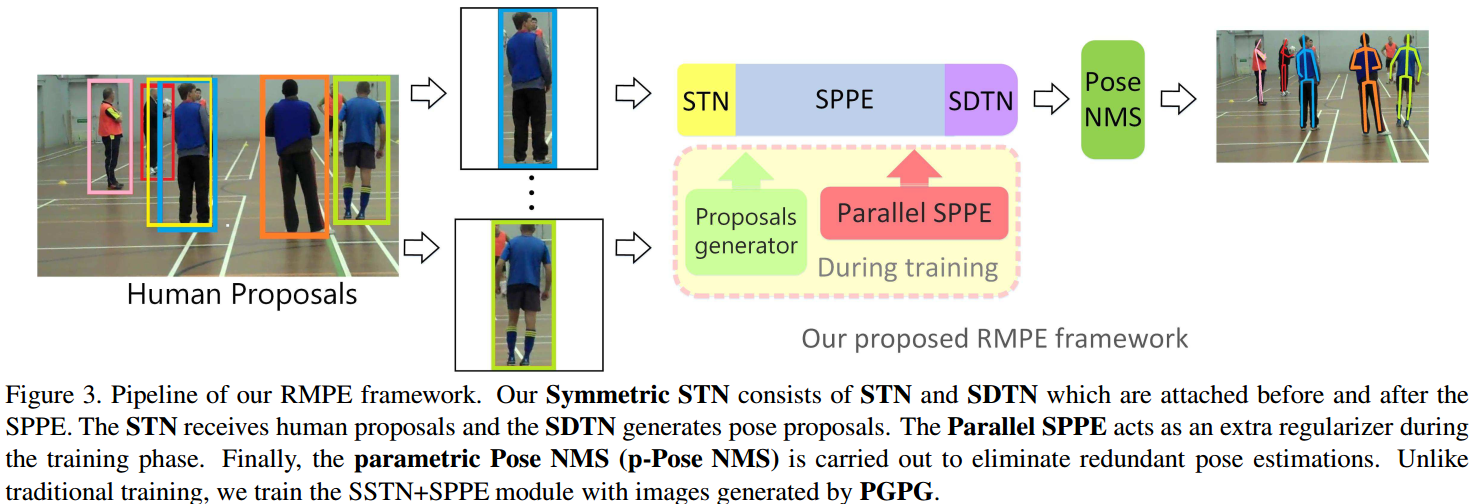
本文试图在人体 bounding box 不准确的情况下精确估计人体姿态. \
人体检测算法: Faster-RCNN, YOLO-v3 et.al. \
姿态估计算法: SPPE Stacked Hourglass model
由于 SPPE 容易受 bbox 准确性的影响, 文章提出了 RMPE 算法.
创新点:
- SSTN: (symmetric STN), 在 bbox 不准确的情况下帮助 SPPE 提取高精度的单人区域;
- parallel SPPE branch
- parametric pose NMS
- PGPG (pose-guided human proposal generator)
Methods
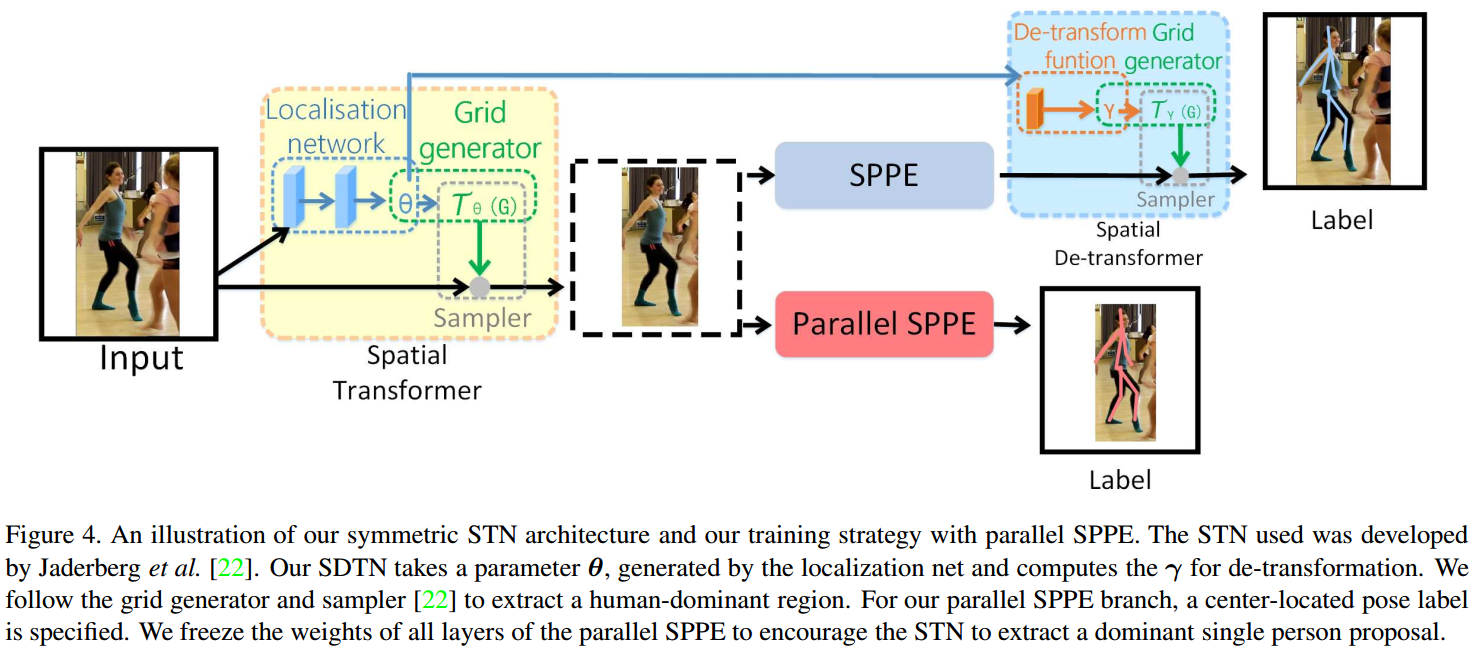
Symmetric STN
- STN: extract high quality dominant human proposals
- SDTN: remap the estimated human pose back to the original image coordinate
Parallel SPPE
Parallel SPPE 只存在于训练过程. parallel SPPE 和 SPPE 共享 STN, 但没有 SDTN. parallel SPPE 的人体 pose label 经过了中心化. 即 SPPE 分支的输出直接和 center-located ground truth poses labels 进行比较.
在训练过程中, 通过冻结 parallel SPPE 的所有层, 该分支所有的层固定, 目的在于回传 center-located pose errors 到 STN 模块.如果 STN 提取的 pose 并不是 center-located, pallel SPPE 将回传更大的误差. 通过这种方式, STN 将聚焦于正确的区域并提取高质量的人体区域.
测试过程中, parallel SPPE 分支被砍掉.
讨论
parallel SPPE 被当成是正则化策略, 帮助避免了局部极小值, 即该种情况下 STN 并没有将提取的人体变换到中间区域.
Parametric Pose NMS
剔除准则:\
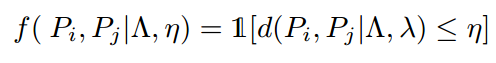
Pose Distance\
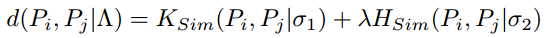
其中, \
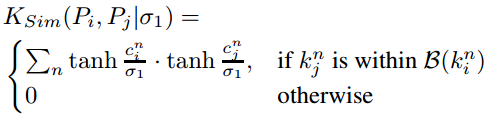
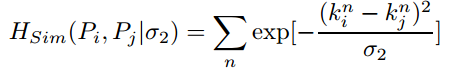
Pose-guided Proposals Generator
Insight: 由于姿态差异, 检测边框和标注边框的相关偏差分布会发生变化.
Implementation: 将学习 $P(\delta B|P)$ 转化为学习 $P(\delta B|atom(P))$
- 对齐所有姿态以保证躯干部分具有相同的长度;
- 使用 k-means 聚类对齐后的姿态;
- 计算 atomic poses 的聚类中心;
- 每个人体实例共享相同的 atomic pose $a$, 进一步计算标注 bbox 和检测 bbox 的偏差;
- 归一化偏差;
- 使用高斯混合分布拟合数据, 不同的 atomic pose 具有不同的高斯混合参数.
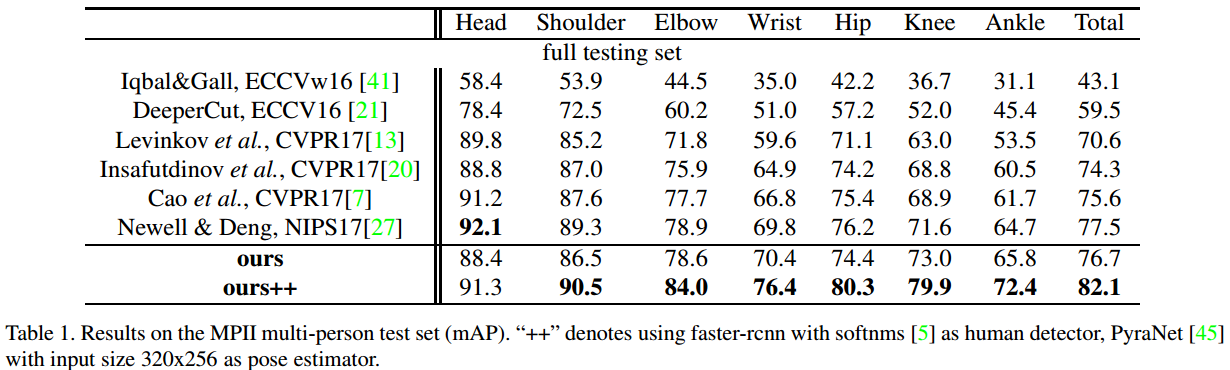
Experiments
- 检测 bbox 的 height, width 各扩展 30% 以保证整个人体区域被提取到;
- 单人姿态估计器: stacked hourglass model
- STN 采用 ResNet-18 (这个网络太大了!)
- parallel SPPE: 4-stack hourglass network.